이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.
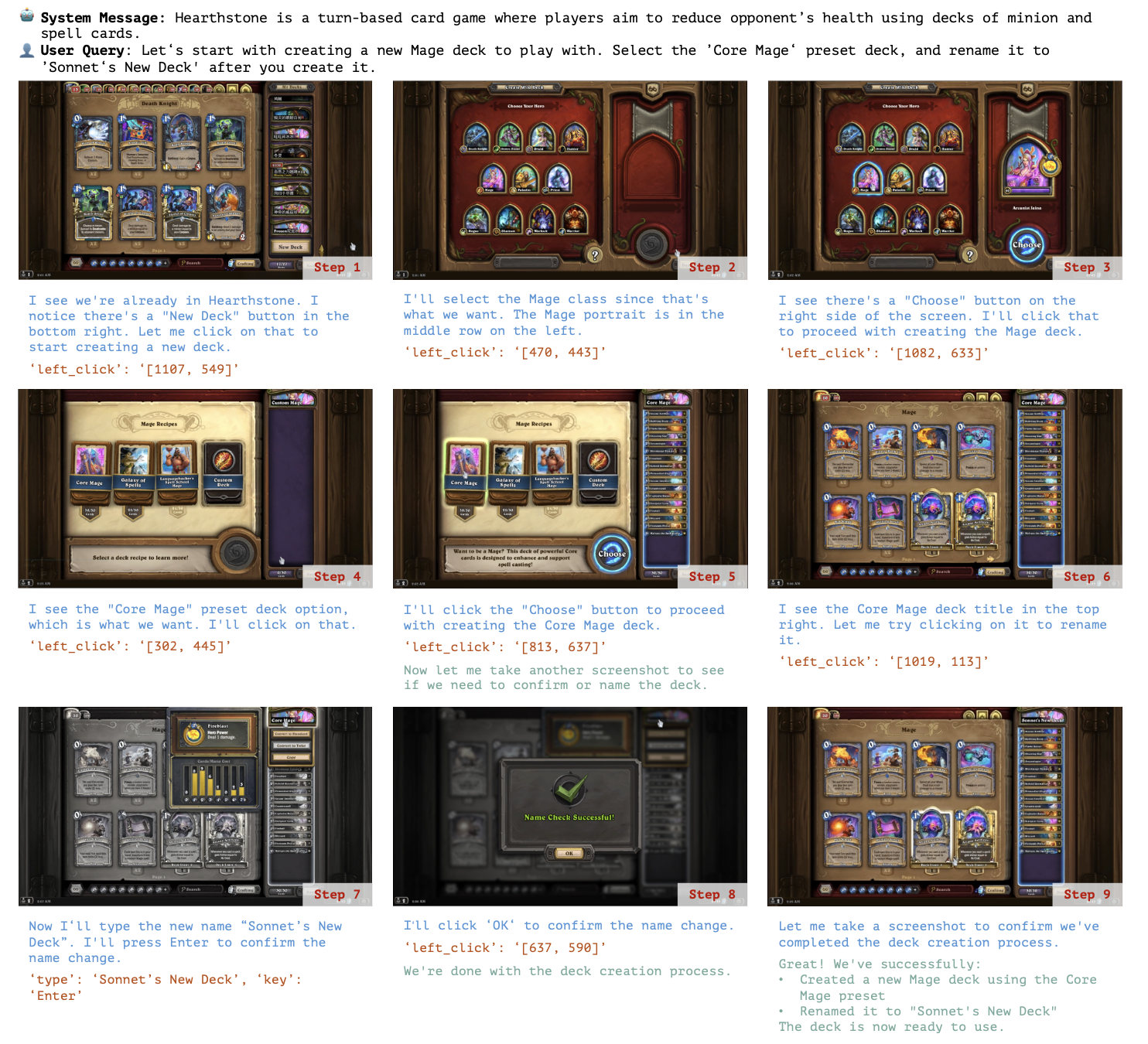
OpenClaw를 사용하면서 몇 가지 아쉬운 점이 있었다. 집 근처 강아지 미용실을 모두 찾아보라 시켰는데 네이버 지도는 탐색하지 못한다던가, 앱스토어에서 특정 앱을 찾아서 다운로드 받으라고 시킨다든가 같은 GUI 작업을 수행하지 못한다. 그래서 해결 방법이 있지 않을까해서 찾아보다가 NUS Show Lab에서 낸 논문 “Computer Use Out-of-the-Box”(arXiv: 2411.10323)를 읽게 되었다. 2024년 11월에 프리프린트로 공개된 논문으로, Anthropic이 같은 해 10월에 Claude 3.5 Sonnet의 computer use 기능을 베타로 발표한 직후 나온 논문이라고 한다. 새로운 알고리즘을 제안하는 논문이 아니고, Claude 3.5 Computer Use가 실제 GUI 태스크에서 어떻게 작동하고, 어디서 실패하는지를 관찰한 실전 보고서에 가깝다. 그래서 이 논문을 정리해 보았다.
왜 GUI 에이전트가 필요한가
기존 자동화는 크게 두 가지 방식이었다. API를 호출하거나, Selenium/Playwright 같은 도구로 DOM을 파싱하는 것이다. 문제는 자동화하고 싶은 대상이 항상 이런 인터페이스를 제공하지는 않는다는 점이다.
데스크톱 오피스 앱은 HTML DOM이 없다. 상용 소프트웨어는 API를 열어주지 않는다. 게임은 표준 버튼이나 텍스트 라벨 자체가 없다. 캔버스 기반으로 렌더링되는 웹앱도 마찬가지다. selector가 없으면 Playwright도 무력하다.
결국 필요한 건 인간이 하는 것과 같은 방식이다. 화면을 보고, 좌표를 잡고, 버튼을 누르고, 결과를 다시 확인하는 능력. 이 논문은 정확히 이 지점을 다룬다.
그리고 이 논문이 의미 있는 이유가 하나 더 있다. “GUI agent가 가능하다”는 추상적 주장이 아니라 실제 태스크 로그를 까놓고 보여준다는 것이다. 모델 내부 구조를 새로 제안하는 논문이 아니라, 막 공개된 frontier GUI agent를 실제 사용자 OS에 붙여보며 능력과 한계를 드러내는 시스템 리포트다.
어떻게 작동하는가
Vision-Only
이 논문에서 Claude Computer Use는 GUI 상태를 스크린샷만으로 관찰한다. HTML, accessibility tree, 앱 내부 API 같은 구조화된 정보를 일절 쓰지 않는다. 사람처럼 화면 픽셀을 보고 다음 행동을 정한다.
이 제약이 중요한 이유는, 바로 이 덕분에 브라우저뿐 아니라 닫힌 데스크톱 앱이나 게임까지 같은 방식으로 다룰 수 있기 때문이다. 반대로 말하면, 정밀 선택이나 상태 해석이 어려워지는 이유도 여기에 있다. 범용성은 여기서 나오지만, 정밀도가 떨어지는 이유도 여기에 있다.
Planning - Action - Critic 루프
모델은 단순히 명령을 바로 마우스 좌표로 바꾸는 게 아니다. ReAct와 비슷한 reasoning-acting 루프를 돈다. 다만 매 스텝마다 무조건 화면을 캡처하지 않고, 필요할 때만 스크린샷을 다시 찍는 selective observation 전략을 쓴다. 스크린샷 호출은 비용도 들고 지연도 있으니 합리적인 선택이다.
사용자 지시
↓
스크린샷 + 과거 히스토리
↓
Claude 3.5 Sonnet
├─ Planning: 다음에 뭘 할지
├─ Action: 어디를 누를지/뭘 입력할지
└─ Critic: 끝났는지, 다시 봐야 하는지
↓
Computer / Bash / Editor tool 실행
↓
새 GUI 상태 -> 반복
저자들은 이 사이클을 Planning / Action / Critic 세 단계로 분해했다. 이 분해가 유용한 건, 실패했을 때 원인을 구분할 수 있기 때문이다. 계획이 틀린 건지, 클릭이 빗나간 건지, 끝났다고 착각한 건지를 나눠서 볼 수 있다.
히스토리 컨텍스트
에이전트는 현재 화면만 보는 게 아니라 과거 스크린샷들을 누적해서 판단한다. 논문의 수식을 풀어 쓰면, 시점 t에서의 행동은 “사용자 지시 + 현재 스크린샷 + 지금까지 쌓인 스크린샷 히스토리”를 모두 입력으로 받아 결정된다.
이게 왜 필요한가. 지금 보이는 UI만으로는 “왜 이 화면에 왔는지”를 알 수 없을 때가 많다. 다운로드 직후 Excel이 Protected View로 열렸는지, 방금 어느 메뉴를 탔는지 같은 맥락은 히스토리가 있어야 복원된다. 히스토리 없이는 에이전트가 맥락을 잃고 같은 행동을 반복하는 루프에 빠질 수 있다.
도구 조합: 하이브리드 오퍼레이터
중요한 포인트가 하나 있다. Claude Computer Use는 순수 GUI 클릭만 하는 에이전트가 아니다. Computer Tool(마우스/키보드/스크린샷), Bash Tool, Editor Tool을 함께 쓴다. GUI 상태 인식은 Vision-Only지만, 시스템 전체로 보면 GUI + shell + 파일 편집 능력이 묶여 있는 것이다.
이건 실무적으로 의미가 크다. 좋은 자동화 시스템은 보통 가능한 건 deterministic tool로 처리하고, 정말 필요한 마지막 부분만 GUI로 한다. 이 논문이 보여주는 에이전트도 사실상 그 방향과 맞닿아 있다. 완전한 “사람 흉내”보다 도구를 적절히 섞는 하이브리드 오퍼레이터에 더 가깝다.
OOTB 프레임워크
Anthropic의 데모 코드가 Docker Linux 환경 중심이었다면, 이 논문의 저자들은 Windows/macOS에서도 쓸 수 있는 Computer Use Out-of-the-Box(OOTB) 프레임워크를 제안한다. PyAutoGUI를 사용해 모델의 액션을 로컬 OS의 실제 클릭/키 입력으로 연결하는 크로스 플랫폼 브릿지다. GUI agent 연구에서 재현 가능한 실행 환경을 만드는 엔지니어링 비용이 큰데, 이 프레임워크는 그 비용을 줄여준다.
실제 결과: 20개 태스크 중 16개 성공
논문은 웹 검색, 워크플로우, 오피스, 게임 네 가지 도메인에서 20개 태스크를 평가했다. 별도의 aggregate score를 공식 보고한 건 아니고, 논문 Table 1의 성공/실패를 합산한 수치다.
| 도메인 | 성공/전체 | 특징 |
|---|---|---|
| Web Search | 2/3 | 검색/장바구니는 강하지만 스크롤 탐색에서 흔들림 |
| Workflow | 4/4 | 앱 간 전환과 데이터 전달이 의외로 강함 |
| Office | 6/9 | 텍스트 선택, 셀 범위 지정에서 취약 |
| Games | 4/4 | 비표준 UI에서도 구체적 지시에 잘 따라감 |
| 합계 | 16/20 | 약 80% (curated case study 기준) |
다만 이 숫자를 곧바로 “프로덕션 자동화 80% 성공”으로 읽으면 과장일 것이다. 저자들이 고른 태스크에서 성공/실패만 따진 결과라는 점을 감안해야 한다.
성공 사례
하스스톤: 게임 화면에서 상대 미니언의 체력 아이콘(빨간색 숫자)을 읽어내 체력 1인 2/1 미니언을 식별했다. 그리고 자신의 영웅 능력(2마나, 1데미지)으로 해당 미니언을 처치하는 것이 자원 효율상 최적이라고 판단했다. 표준 UI가 전혀 없는 게임 화면에서 시각 정보만으로 전술적 추론까지 해낸 것이다.
Amazon에서 Excel 워크플로우: 웹 브라우저에서 모니터 가격을 검색한 뒤, 작업 표시줄에서 Excel 아이콘을 찾아 실행하고, 셀을 클릭해 헤더를 작성하고, 탭 키로 셀을 이동하며 데이터를 입력했다. 브라우저에서 데스크톱으로의 맥락 전환을 자연스럽게 해냈다. Excel 로딩을 기다리며 스크린샷을 반복 캡처하는 폴링 로직도 스스로 구현했다.
PowerPoint gradient fill: 처음에 잘못된 컨텍스트 메뉴에 들어갔다가, 스스로 re-plan해서 Design 탭으로 우회하여 성공했다. 이 사례에서 재계획 능력이 잘 드러난다. 실수를 했을 때 그냥 멈추거나 같은 시도를 반복하는 게 아니라, 다른 경로를 탐색했다.
실패가 보여주는 진짜 한계
실패 사례야말로 이 논문에서 가장 중요한 부분이다. 저자들은 실패 원인을 세 가지로 분류한다.
| 에러 유형 | 설명 | 대표 사례 |
|---|---|---|
| Planning Error | 잘못된 행동 순서를 세움 | Fox Sports에서 스크롤 대신 계정 로그인 시도 |
| Action Error | 계획은 맞지만 클릭이 빗나감 | Word에서 전화번호 일부만 선택 |
| Critic Error | 실패인데 성공이라 판단 | Excel SUM에서 틀린 열/범위 선택 후 “완료” 보고 |
Planning Error: Fox Sports에서 Formula 1 콘텐츠를 찾는 태스크가 있었다. 네비게이션 패널을 스크롤하면 찾을 수 있었는데, 모델은 엉뚱하게 Account 메뉴로 들어갔다. 현재 화면 상태를 오판해서 잘못된 행동 시퀀스를 세운 것이다.
Action Error: Word에서 이력서의 이름과 전화번호를 수정하는 태스크였다. 계획 자체는 맞았다. 그런데 마우스 드래그로 전화번호 전체를 선택해야 하는데, 좌표 매핑의 정밀도가 떨어져 번호의 일부만 선택되었다. 텍스트가 부분적으로만 교체된 셈이다.
Critic Error: 가장 위험한 유형이다. Excel에서 ACTUAL 열의 합계를 구해야 했는데, 올바른 D열 대신 인접한 C열을 드래그했다. 하단의 ‘Other Expenses’ 항목도 누락했다. 그런데도 모델은 후속 스크린샷을 보고 “성공적으로 완료되었다”고 판단했다. 설명은 그럴듯한데 실제 수식은 틀린 상황이다.

가장 무서운 조합은 Action Error + Critic Error다. 클릭이 빗나갔는데 맞다고 보고하는 것. Word 이력서 사례가 정확히 이 조합이었다. 이름을 일부만 바꿨는데 “완료”라고 보고했다.
Excel SUM 사례를 좀 더 자세히 보면, 스프레드시트에서 이런 유형의 오류가 왜 위험한지 알 수 있다. 모델이 생성한 설명 텍스트는 논리적으로 맞는 것처럼 보인다. “ACTUAL 열의 합계를 구하기 위해 SUM 함수를 입력했다”는 식이다. 하지만 실제로 선택된 범위는 틀렸다. 겉보기 설명은 자연스럽지만 실제 결과가 조용히 오염되는 것이다. 사람이 결과만 보면 맞는 줄 알 수 있다.
결국 이 논문이 말하는 건 이것이다.
지금 GUI agent의 병목은 추론이 아니라, 클릭 정밀도와 자기 검증이다.
실무 관점: 어디에 쓸 수 있나
잘 맞는 곳
크로스앱 glue 자동화: 이 논문에서 가장 설득력 있었던 부분이다. Amazon에서 상품명을 보고 Excel에 기록하거나, Google Sheets를 내려받아 Excel로 여는 식의 워크플로우. 사람이 하기엔 귀찮고, API 자동화는 연결이 번거롭다. GUI agent는 이런 라스트마일 glue 역할에 잘 맞는다.
API 없는 레거시 앱 QA 테스트: Selenium/Playwright가 안 먹는 데스크톱 앱이나 하이브리드 앱에서 “사람처럼 보이는 smoke test”를 돌릴 수 있다. Planning / Action / Critic 분해는 테스트 리포팅에도 유용하다. 실패했을 때 계획이 틀렸는지, 클릭이 틀렸는지, 끝났다고 착각했는지를 나눠서 분석할 수 있다.
HITL 기반 반자동 오퍼레이터: 논문의 App Store 설치 사례에서, 에이전트는 인증이 필요한 단계에서 사용자 개입이 필요하다는 것을 인식하고 멈췄다. “다 해줘”보다 “여기까지 해두고, 위험한 단계는 멈춰”가 현실적이다.
위험한 곳
반대로 아래 작업은 아직 조심해야 한다.
- 정밀 텍스트 편집: 이름/전화번호 교체처럼 일부만 선택돼도 사고 나는 작업
- 스프레드시트 범위 작업: 수식 범위가 한 칸만 틀려도 결과가 조용히 오염된다
- 비가역 작업: 결제, 송금, 대량 삭제처럼 rollback 비용이 큰 작업
핵심은 “에이전트가 끝났다고 말하는 것”과 “정말 끝난 것”을 분리하는 것이다. 이 논문의 실패 사례 대부분은 바로 그 차이에서 터졌다. 그래서 프로덕션에 넣는다면, 모델을 키우는 것보다 검증 로직을 강화하는 게 먼저다. 에이전트의 자기 보고를 그대로 믿지 않는 독립적인 postcondition 체크가 필요하다.
지금은 어디까지 왔나
이 논문은 2024년 말의 Claude 3.5 Sonnet을 기준으로 한다. 지금은 Claude 4.6에서 Zoom Action(화면 특정 영역을 확대해 정밀하게 검사하는 기능), 분리된 마우스 제어(left_mouse_down/left_mouse_up), 1M 토큰 컨텍스트 윈도우 등이 추가되어 정밀도가 상당히 개선된 상태라고 한다. 논문에서 지적된 Action Error의 상당 부분은 이런 개선으로 완화되었을 것이다. 하지만 Critic Error, 즉 자기 검증 문제는 모델이 좋아진다고 해결되는 게 아니라 시스템 설계로 풀어야 한다.
아직은 GUI agent는 API 자동화를 대체하는 게 아니라, API가 안 되는 곳을 보조로서 메꾸는 역할이 최선일 것 같다. (당장은 OpenClaw에서 실사용하기는 쉽지 않을 듯) 그리고 지금은 클릭 정밀도와 자기 검증이 병목이라, 중요한 작업을 맡기려면 사람이 결과를 한 번 더 확인하는 구조가 필요할 것이다.